
爬虫 6 selenium调动浏览器爬数据
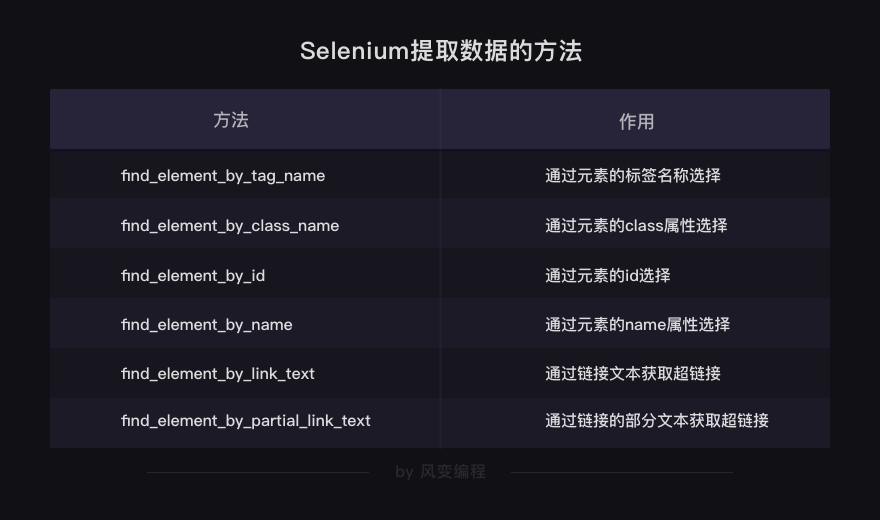
# 以下方法都可以从网页中提取出'你好,蜘蛛侠!'这段文字
find_element_by_tag_name:通过元素的名称选择
# 如<h1>你好,蜘蛛侠!</h1>
# 可以使用find_element_by_tag_name('h1')
find_element_by_class_name:通过元素的class属性选择
# 如<h1 class="title">你好,蜘蛛侠!</h1>
# 可以使用find_element_by_class_name('title')
find_element_by_id:通过元素的id选择
# 如<h1 id="title">你好,蜘蛛侠!</h1>
# 可以使用find_element_by_id('title')
find_element_by_name:通过元素的name属性选择
# 如<h1 name="hello">你好,蜘蛛侠!</h1>
# 可以使用find_element_by_name('hello')
#以下两个方法可以提取出超链接
find_element_by_link_text:通过链接文本获取超链接
# 如<a href="spidermen.html">你好,蜘蛛侠!</a>
# 可以使用find_element_by_link_text('你好,蜘蛛侠!')
find_element_by_partial_link_text:通过链接的部分文本获取超链接
# 如<a href="https://localprod.pandateacher.com/python-manuscript/hello-spiderman/">你好,蜘蛛侠!</a>
# 可以使用find_element_by_partial_link_text('你好')
Chrome驱动下载:https://localprod.pandateacher.com/python-manuscript/crawler-html/chromedriver/ChromeDriver.html

